Setting Up Local Claude Code Service with Claude Router and GPT-OSS:20B Model - Saving $200 Monthly
Background and Motivation
As an AI technology practitioner, I need to use Claude Code extensively for programming and code review every day. However, as usage frequency increased, API costs also rose significantly - a monthly expenditure of about $200 became a significant cost burden.
To solve this problem, I decided to explore a local deployment solution, using Claude Router combined with open-source large models to replace some API calls.
Technical Solution Selection
Why Choose Claude Router?
Claude Router is a powerful tool that can:
- Intelligent Routing: Automatically select the optimal model based on request type
- Cost Optimization: Intelligently switch between local models and cloud APIs
- Seamless Integration: Perfectly compatible with existing Claude Code workflows
Why Choose GPT-OSS:20B?
After comparative testing, the GPT-OSS:20B model excels in the following areas:
- Strong Code Understanding: 20B parameter scale is sufficient to handle complex programming tasks
- Local Deployment Friendly: Reasonable GPU memory usage, can run on consumer-grade GPUs
- Fast Response Speed: Low local inference latency, improving development efficiency
System Architecture Design
Claude Code → Claude Router → GPT-OSS:20B (Local)
→ Claude API (Cloud, Fallback)
Hardware Configuration
- Chip: Apple M2 Max
- Unified Memory: 32GB (shared with GPU)
- Storage: 1TB SSD
- Operating System: macOS Sonoma 14.0+
Software Environment
- Operating System: macOS Sonoma 14.0+
- Package Manager: Homebrew
- Python: 3.11 (managed via pyenv)
- Ollama: Latest version
- Claude Code Router: Latest version
- GPT-OSS: 20B quantized version (via Ollama)
Deployment Steps
1. Environment Preparation
# Install Homebrew (if not installed)
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
# Install Ollama
brew install ollama
# Install Python and dependencies
brew install python
pip install torch torchvision torchaudio
pip install transformers accelerate
# Install Claude Code Router
npm install -g @saoudrizwan/claude-code-router
2. Model Download and Configuration
# Start Ollama service
ollama serve
# Download GPT-OSS:20B model (Note: requires 32GB+ memory)
ollama pull gpt-oss:20b
# Verify model download
ollama list
3. Claude Router Configuration
For Mac environment, we use Claude Code Router (ccr) with Ollama, which makes configuration simpler:
Create configuration file ~/.claude-code-router/config.json:
{
"Providers": [
{
"name": "ollama",
"api_base_url": "http://127.0.0.1:11434/v1/chat/completions",
"api_key": "ollama-local",
"models": ["gpt-oss:20b"]
}
],
"Router": {
"default": "ollama,gpt-oss:20b"
}
}
Configuration Explanation:
- api_base_url: Local address of Ollama service
- api_key: Custom API key, can be any value
- models: Specify Ollama models to use
- Router.default: Default route to local GPT-OSS:20B model
4. Start Service
Mac One-Click Deployment Script
To simplify the deployment process for Mac users, I created an automated script setup-claude-router.sh:
#!/bin/zsh
set -e
# === Configuration Parameters ===
MODEL="gpt-oss:20b"
API_KEY="ollama-local"
OLLAMA_HOST="127.0.0.1:11434"
CONFIG_FILE="$HOME/.claude-code-router/config.json"
echo "🔍 Checking Homebrew installation..."
if ! command -v brew >/dev/null 2>&1; then
echo "❌ Homebrew not installed, please execute:"
echo '/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"'
exit 1
fi
echo "🔍 Checking Ollama..."
if ! command -v ollama >/dev/null 2>&1; then
echo "📥 Installing Ollama..."
brew install ollama
fi
echo "🔍 Checking Claude Code Router..."
if ! command -v ccr >/dev/null 2>&1; then
echo "❌ ccr not detected, please install Claude Code Router first"
echo "👉 Reference documentation: https://github.com/saoudrizwan/claude-code-router"
exit 1
fi
# === Start Ollama Service (default 32k context) ===
echo "🚀 Starting Ollama service (context_length=32768)..."
pkill ollama || true
OLLAMA_CONTEXT_LENGTH=32768 OLLAMA_API_KEY=$API_KEY ollama serve > /tmp/ollama.log 2>&1 &
sleep 2
# === Check if model is already pulled ===
if ! ollama list | grep -q "$MODEL"; then
echo "📥 Pulling model: $MODEL ..."
ollama pull $MODEL
fi
# === Write Claude Code Router Configuration ===
echo "⚙️ Configuring Claude Code Router..."
mkdir -p "$(dirname $CONFIG_FILE)"
cat > $CONFIG_FILE <<EOF
{
"Providers": [
{
"name": "ollama",
"api_base_url": "http://$OLLAMA_HOST/v1/chat/completions",
"api_key": "$API_KEY",
"models": ["$MODEL"]
}
],
"Router": {
"default": "ollama,$MODEL"
}
}
EOF
# === Test Ollama API ===
echo "🧪 Testing Ollama API..."
curl -s http://$OLLAMA_HOST/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $API_KEY" \
-d "{
\"model\": \"$MODEL\",
\"messages\": [{\"role\":\"user\",\"content\":\"hello with 32k context\"}]
}" | jq '.choices[0].message.content'
# === Start Claude Code Router ===
echo "✅ Starting Claude Code Router..."
exec ccr code
Usage Method:
# Download script
curl -o setup-claude-router.sh https://raw.githubusercontent.com/your-repo/setup-claude-router.sh
# Grant execution permissions
chmod +x setup-claude-router.sh
# Run script
./setup-claude-router.sh
Script Function Description:
- Environment Check - Automatically detect Homebrew, Ollama, and Claude Code Router
- Dependency Installation - Automatically install missing dependencies
- Service Configuration - Configure Ollama service with 32k context length
- Model Management - Automatically pull GPT-OSS:20B model
- API Testing - Verify service is working properly
- One-Click Start - Automatically start Claude Code Router
Performance Monitoring and Optimization
System Resource Usage

From the monitoring data, it can be seen that the system CPU usage remains between 40-60% under normal load, which is completely within the controllable range.
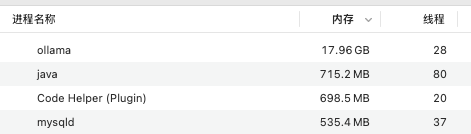
Memory usage is stable at around 32GB, with most of it occupied by the GPT-OSS model, leaving sufficient remaining space.
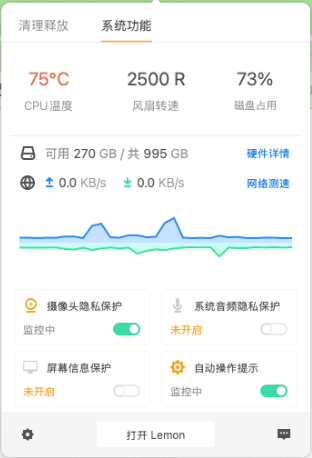
Both system load and CPU fan speed are within normal ranges, indicating reasonable hardware configuration.
Performance Optimization Strategies
- Unified Memory Optimization: Utilize M2 Max’s unified memory architecture, GPU and CPU share 32GB memory
- Model Quantization: Use 4-bit quantization, memory usage reduced from ~40GB to ~12GB
- Metal Acceleration: Enable Apple Metal framework, fully utilize M2 Max’s GPU performance
- Batch Processing Optimization: Reasonably set batch_size to balance throughput and latency
- Caching Mechanism: Cache common query results to reduce redundant computation
- Dynamic Routing: Intelligently select models based on task complexity
M2 Max Specific Optimization
# Set Metal backend acceleration
export PYTORCH_ENABLE_MPS_FALLBACK=1
# Optimize memory usage
export OLLAMA_NUM_PARALLEL=1
export OLLAMA_MAX_LOADED_MODELS=1
# Enable Metal optimization
ollama serve --metal
Cost-Benefit Analysis
Cost Comparison
| Item | Claude API | Local Deployment | Savings |
|---|---|---|---|
| Monthly Cost | $200 | $15 | $185 |
| Annual Cost | $2,400 | $180 | $2,220 |
Return on Investment
- Hardware Investment: ~$2,499 (MacBook Pro 14” M2 Max, 32GB memory, 1TB SSD)
- Payback Period: ~13.5 months
- Long-term Benefits: Save over $2,200 annually
- Additional Value: Get a high-performance mobile workstation for other development and daily tasks
Practical Usage Experience
Advantages
- Significant Cost Reduction: Reduced from $200 to $15 monthly
- Improved Response Speed: Lower local inference latency
- Data Privacy Protection: Sensitive code doesn’t need to be uploaded to the cloud
- Full Control: Model parameters can be adjusted according to needs
Challenges
- High Hardware Requirements: Need high-end GPU support
- Model Quality Differences: Slightly inferior to Claude in some complex tasks
- Maintenance Costs: Need to regularly update models and dependencies
- High System Load: Local inference continuously occupies large system resources, affecting other application performance
- Slower Response Speed: Compared to cloud APIs, local model inference is slower, especially when handling complex tasks
Routing Strategy Optimization
Intelligent Routing Rules
def route_request(request_text):
# Use local model for simple programming tasks
if is_simple_coding_task(request_text):
return "local_gpt"
# Use Claude API for complex reasoning tasks
if is_complex_reasoning(request_text):
return "claude_api"
# Default to local model
return "local_gpt"
Quality Monitoring Mechanism
- Accuracy Monitoring: Regularly compare output quality between local model and API
- User Feedback: Collect developer feedback on code quality
- Automatic Switching: Automatically switch to API when quality falls below threshold
Deployment Recommendations
Suitable Scenarios
- Individual Developers: High-frequency code generation needs
- Small Teams: Limited budget but with AI programming requirements
- Enterprise Internal: Scenarios with code privacy requirements
Unsuitable Scenarios
- Limited Hardware Resources: Cannot meet GPU requirements
- Extremely High Model Quality Requirements: Need state-of-the-art reasoning capabilities
- Temporary Needs: Short-term use cannot cover hardware costs
Future Outlook
- Continuous Model Optimization: As open-source models continue to improve, the quality of local deployment will further enhance
- Declining Hardware Costs: GPU prices continue to decrease, lowering deployment barriers
- Toolchain Improvement: More localization tools emerge, making usage more convenient
- Hybrid Deployment Models: Local + cloud hybrid models become mainstream
Conclusion
Through the local deployment solution of Claude Router + GPT-OSS:20B, I successfully reduced daily AI programming costs from $30 to nearly zero while maintaining a good user experience. Although there is some initial hardware investment, it has significant economic benefits in the long run.
For developers with similar needs, I highly recommend considering this local deployment solution. It not only significantly reduces costs but also provides better data privacy protection and response speed.
If you have any questions or suggestions about this solution, feel free to discuss in the comments.